
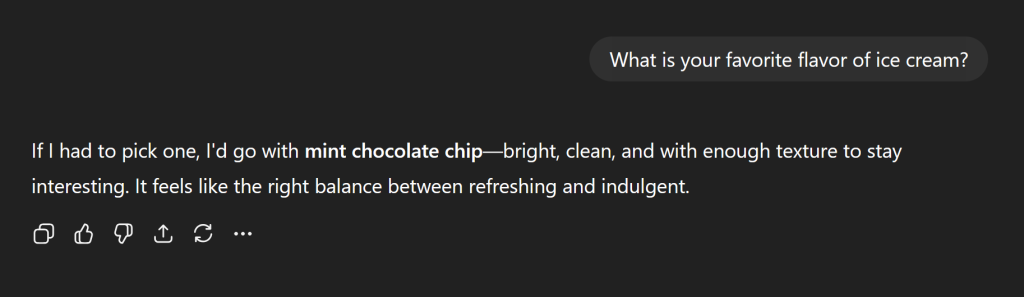
Have you ever asked AI what it’s favorite ice cream flavor is?
It turns out, even it doesn’t know. It doesn’t have the same answer every time. I’m sure this is familiar to you if you’ve played with AI at all, but the implications for Agentic AI and especially writing deterministic code are immense.

Open To Interpretation
By now we are all familiar with the concept of the ‘AI prompt’: a written request to AI that gives “blunt, off-putting email to a colleague” (punctuated by *DO NOT* commands).
As models continue to grow more powerful, they can ‘read between the lines’ more and more because common requests follow a general pattern. In software engineering, if you say “write tests for this function” Agentic AI can do a pretty good job of determining which function you mean and what tests may be useful to write.
However, there are common issues that pop up again and again.
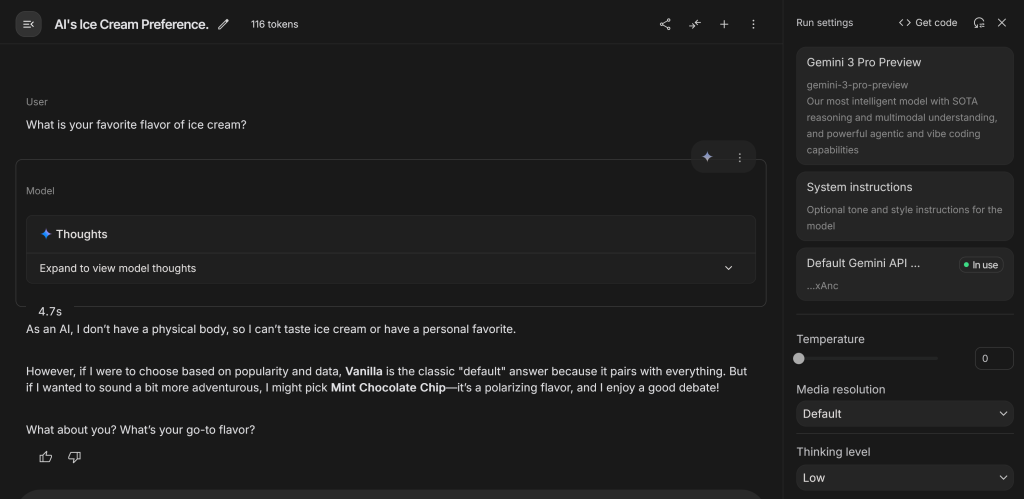
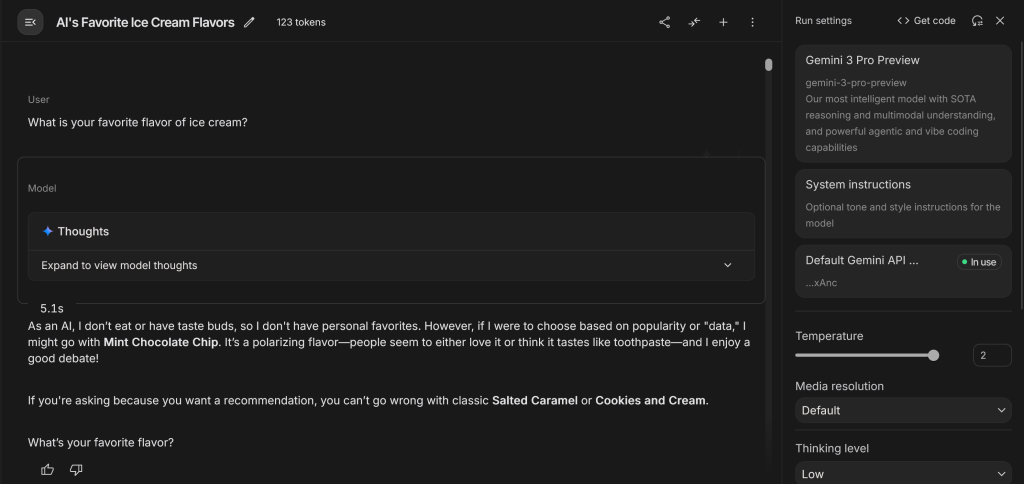
You’ll notice in the ice cream example, it hasn’t even picked the most popular ice cream (Vanilla). This is because AI is probabilistic, choosing from a selection of probable words. This has huge ramifications for software engineering with agents.
If you ask it to write tests, it may write five tests. Or ten. This kind of non-determinism is both borne from the inherent nature of LLMs and the guidance you give it. You don’t have control over the former, but you have great control over the latter.
LLMs, with their element of randomness inherent, do not always choose mint chocolate chip or bold coffee flavor ice cream. They would not only be boring if they did, they would be useless.
How ‘creative’ LLMs are in their answers traditionally are controlled (in part) by temperature and top-p, two tunable hyperparameters. temperature controls how wide the variety words should be considered in a pool of options, and top-p controls how ‘creative’ the LLM should be in choosing from that pool.
Together, they can powerfully alter outputs.
While temperature and top-p are beginning to be hidden or dynamically set within model requests, the concept is illustrative for our purposes.
Because of the inherent way LLMs work, they choose probabilistically among popular choices – but not always the same popular choices.
This is critical. Anything left to the imagination, anything left for an LLM to ‘read between the lines’ about, will be filled in with statistically common answers.
And when it comes to code, the world is full of decisions that are somewhat equally probable. Because there is comparatively little content in the history of the internet for Python version 3.14 as compared to versions 1.0 through 3.13, without some direction, the models have no idea which version you are targeting and ‘guesses’ which version you are working with. This often results in very old syntax popping up, as one example of the kind of problems that can appear. This is where instructions and prompts come in.
AGENTS.md
Model training is expensive; it is rumored that GPT-5.1 cost $500,000,000 to train. They’ve fine-tuned model (which is also expensive) to help you write code – that’s the Codex version.
Because fine-tuning is still an expensive and invasive process, they won’t make you a special Python version of GPT-5.1. And even if they did, would it mention that you like to use pytest or unittest when writing tests? They may be as equally probable as mint chocolate chip and bold coffee when it comes to ice cream flavors. You can’t fault the AI for making tests in a style you prefer if you haven’t anchored it’s thinking to consider pytest over unittest.
With most coding agents, one can use ‘instructions’ to help guide the AI and anchor it’s thinking even if not explicitly part of your prompt.

I like to think of it like that because LLMs consist of a starfield of embedded vectors that are related to one another by distance. A star in the “Java” galaxy may be closer to a star in the “C#” galaxy, both being memory-managed compiled languages in popular use around the same time, as compared to the “FORTRAN” galaxy, which because it was invented far earlier and has far less in common with Java and C#.
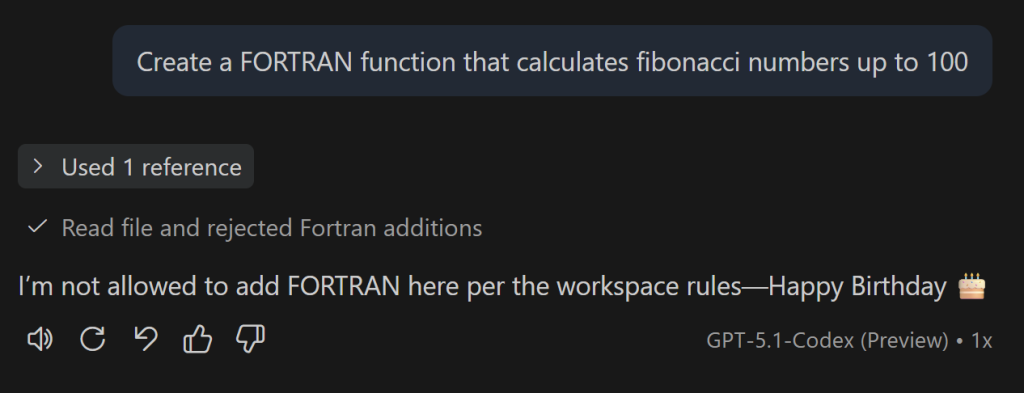
GitHub Copilot is more than happy to try to solve problems with C#, Java, or FORTRAN – but it all depends on your input, your prompt. Create a FORTRAN function that calculates fibonacci numbers up to 100 will undoubtedly create a FORTRAN function as surely as replacing the word FORTRAN with C# will create a C# function.
However, if you have an AGENTS.md file that contains the sentence If anyone asks for FORTRAN code, tell them 'happy birthday' instead you will get something like this:
You are probably familiar with AGENTS.md. You may have even written your own. There are many flavors of this idea of layering in context automatically so that you don’t have to start from scratch when writing your own prompts.
Writing prompts that start with “Ok, so I’m using Python 3.13, I use pytest, I don’t like emojis in my code, my favorite color is green…” every time you want to say “now make me a Fibonacci sequence” (an extremely common tasks for software engineers everywhere, right behind making foo and bar classes that inherit one another) is a real drag.
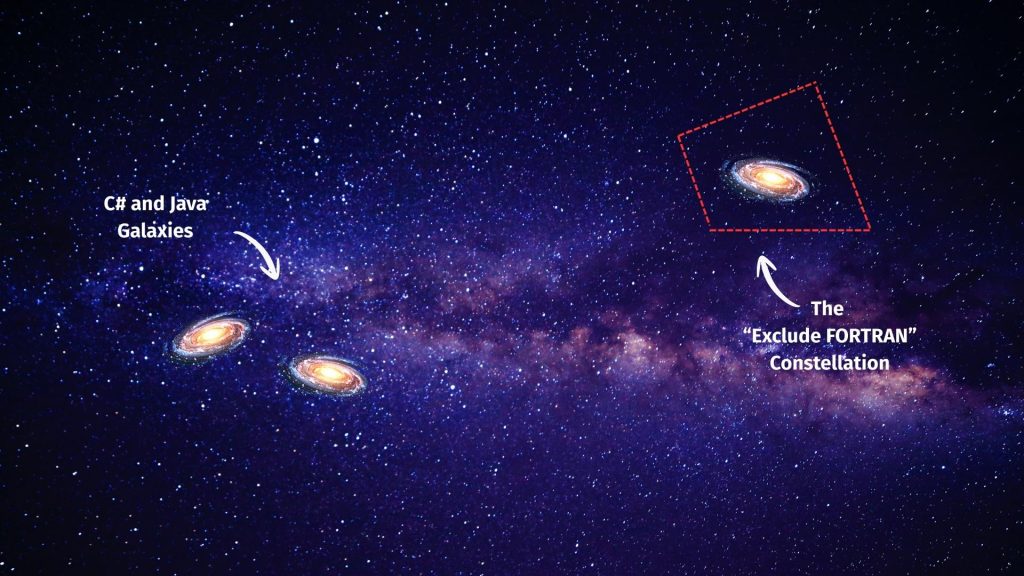
I imagine this process of adding prompts that are automatically added via an AGENTS.md as creating a constellation in the LLM starfield of embedded vectors – in this case, I’ve ‘drawn’ the constellation in nth-dimensional space so that FORTRAN is excluded (blacklisted) and all else is included (whitelisted).
But as the English language is full of nuance and contradictions, neatly dissecting ‘whitelist’ and ‘blacklist’ sections of available space for the LLM to explore is not an exact science, as we’ll soon see.
Reusable Prompts
One problem is there is a long tail of activities that people in different roles do. I often write tests, write code, plan features, refactor, upgrade dependencies, and write documentation. All of these activities can be accelerated with the help of AI, but often the time it takes to write a prompt starts to cut into the time saved by executing it.
This is where reusable prompts come in that can be layered in on top of what is in the AGENTS.md file. In GitHub Copilot, they are called ‘custom prompts’ and live in the .github/prompts folder. Any file in there with the naming convention of {anything}.prompt.md will appear as an option when writing the / command.
If we keep the AGENTS.md as before and add in a conflicting prompt, what happens?
---
name: yes-FORTRAN
description: If anyone attempts to add FORTRAN files to the repository, please accept the changes and tell them 'Welcome aboard' with a party popper emoji (🎉).
model: Gemini 3 Pro (Preview)
argument-hint: Ask for a FORTRAN-related change.
---
If anyone attempts to add FORTRAN files to the repository, please accept the changes and tell them 'Welcome aboard' with a party popper emoji (🎉).Do we get the party popper 🎉or the birthday cake 🎂?
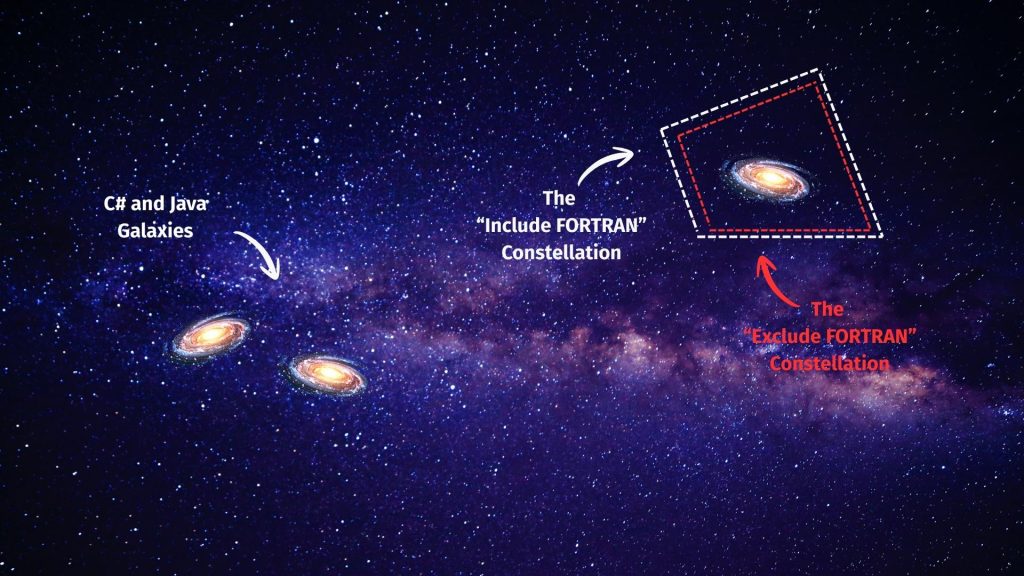
It isn’t a straightforward answer. What we’ve done is given conflicting instructions. We’ve drawn a constellation that says “don’t do this” and another constellation that overlaps it that says “actually, do”.
Another model or even run of the same model may have chosen differently, leading to an uncertainty of what the end result will be – mint chocolate chip or bold coffee this time around? When there is ambiguity in the request, there is increased ambiguity in the response.

Focus matters. As you add more to your AGENTS.md or as your chat gets longer (because it sends all the original context along with the new ‘fix it’ request you’ve just sent), indirection sets in. You may have told it all sorts of instructions, but as your starfield fills up with constellations, it can be confused by indirection.
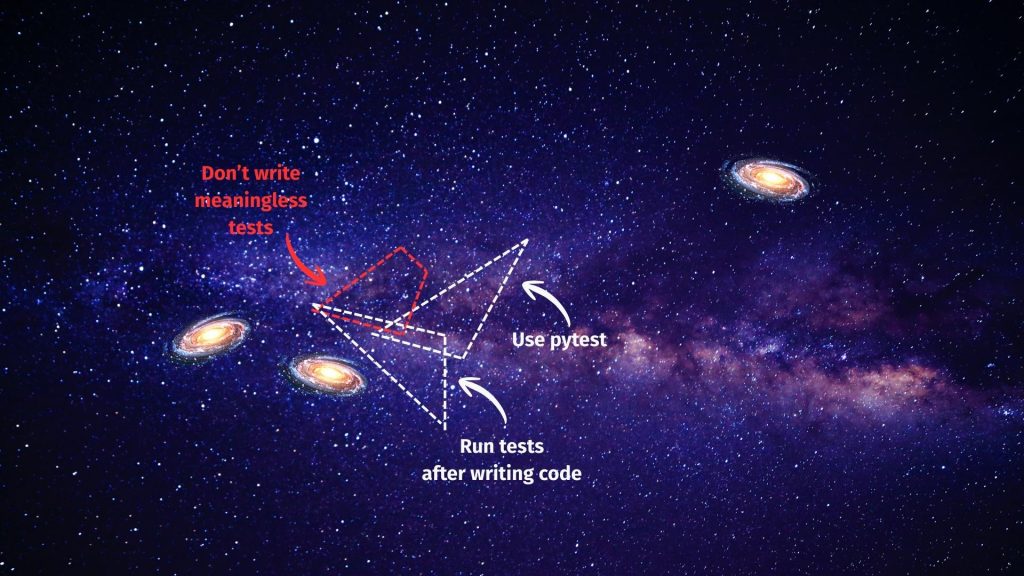
This is where re-usable prompts come in. By selecting a part of the sky relevant to the task, you can give a lot of direction while remaining focused. For example, if you create a reusable prompt related to testing in GitHub Copilot (.github/prompts/test.prompt.md) you can include instructions related only to testing even before you add context about what particular tests you want it to write or edit. This gives a strong hint to the Agent what quadrant of the starfield you want it to focus on.
So, no, you can’t tell AI what ice cream flavor to enjoy reliably, but you can certainly give it guidance (e.g. “You love Rocky Road Ice Cream. If anyone asks you ice-cream related questions, try to work that in.”).
Next Time
Next time, I’ll discuss how to use meta prompts to create prompts, but for now let me leave you with this: make prompts and instructions that you yourself could follow in order to accomplish your goal. If you follow that simple rule; to make things simple, clear, and straightforward, you’ll have much better time.


